Welcome to YourDigitalSelf project!
Personal data is now pervasive, as digital devices are capturing every part of our lives. Users are constantly producing and saving more data or traces, either actively in files, emails, social media interactions, etc., or passively by GPS tracking of mobile devices, or records of financial transactions. These traces do not only consist of a repository of saved documents anymore but rather represent a chronicle of the user’s life, keeping record of where the user went, who the user interacted with (online or in real-life), what the user did, and when.
Unifying personal information from heterogeneous data sources brings a range of challenges. First, access to the data is limited and requires elaborate mechanisms to extract personal data. Sources export views of their data that do not share a common unified schema. Individual entities need to be linked, and their provenance recorded. Second, traditional keyword-based search methods are not appropriate in a setting where users may remember valuable contextual cues to guide the search. Finally, users have individual habits, patterns and interpretations of their data that can be identified and integrated in their personal information database.
Personal Data Integration
Searching Heterogeneous Personal Data
Our work uses frequency-based scoring models that leverage the correlation between users (who), time (when), location (where), data topics (what), and provenance (how) to improve search over personal data. Since the scoring model needs to generalize well over user-specific data sets, we extend our static scoring function by adopting a learning-to-rank approach using the state of the art LambdaMART algorithm. Due to the lack of pre-existing personal training data, a combination of known-item query generation techniques and an unsupervised ranking model (field-based BM-25) is used to build our own training sets. A thorough qualitative evaluation over real user data from a variety of data sources such as Facebook, Dropbox, and Gmail show that our approach significantly improves search accuracy when compared with traditional personal search tools such as Apple’s Spotlight and Apache Solr, and techniques like TF-IDF and BM25.
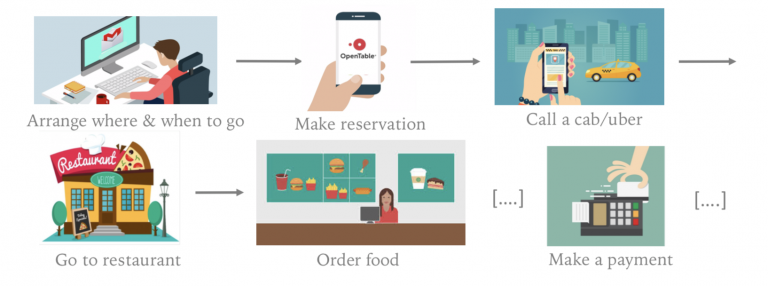
Building a Library of Personal Activity Scripts
Based on research in Psychology that humans maintain a so-called episodic memory of actions, there is strong evidence that to communicate, humans need knowledge of a set of higher level prototypical plans in which users and their community frequently engage in. We call such stereotypical processes “scripts”, and hypothesize that script (instances) help group and organize personal digital traces, as well as abstract information from them. We focus in the creation of a library of everyday activity scripts, which we intend to build upon work in Human Behavior Recognition field and Event-based Media Analysis. Because of the novelty of personal digital traces as a lifelogging media, we investigate crowd-based approaches for script identification and creation through gamification strategies, in order to encourage users in being creative in identifying the personal digital traces involved in a script.